Abstract
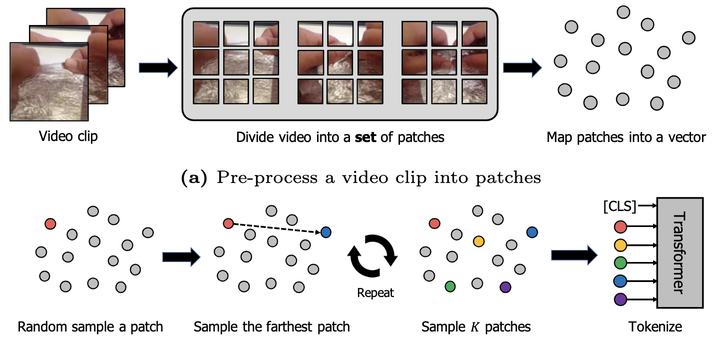
For decades, it has been a common practice to choose a subset of video frames for reducing the computational burden of a video understanding model. In this paper, we argue that this popular heuristic might be sub-optimal under recent transformer-based models. Specifically, inspired by that transformers are built upon patches of video frames, we propose to sample patches rather than frames using the greedy K-center search, i.e., the farthest patch to what has been chosen so far is sampled iteratively. We then show that a transformer trained with the selected video patches can outperform its baseline trained with the video frames sampled in the traditional way. Furthermore, by adding a certain spatiotemporal structuredness condition, the proposed K-centered patch sampling can be even applied to the recent sophisticated video transformers, boosting their performance further. We demonstrate the superiority of our method on Something–Something and Kinetics datasets.